
做一个有温度和有干货的技术分享作者 —— Qborfy
今天我们来学习 强化学习
一句话核心:AI在试错中成长,像小孩学走路,通过奖励/惩罚信号找到最优行为策略
是什么?
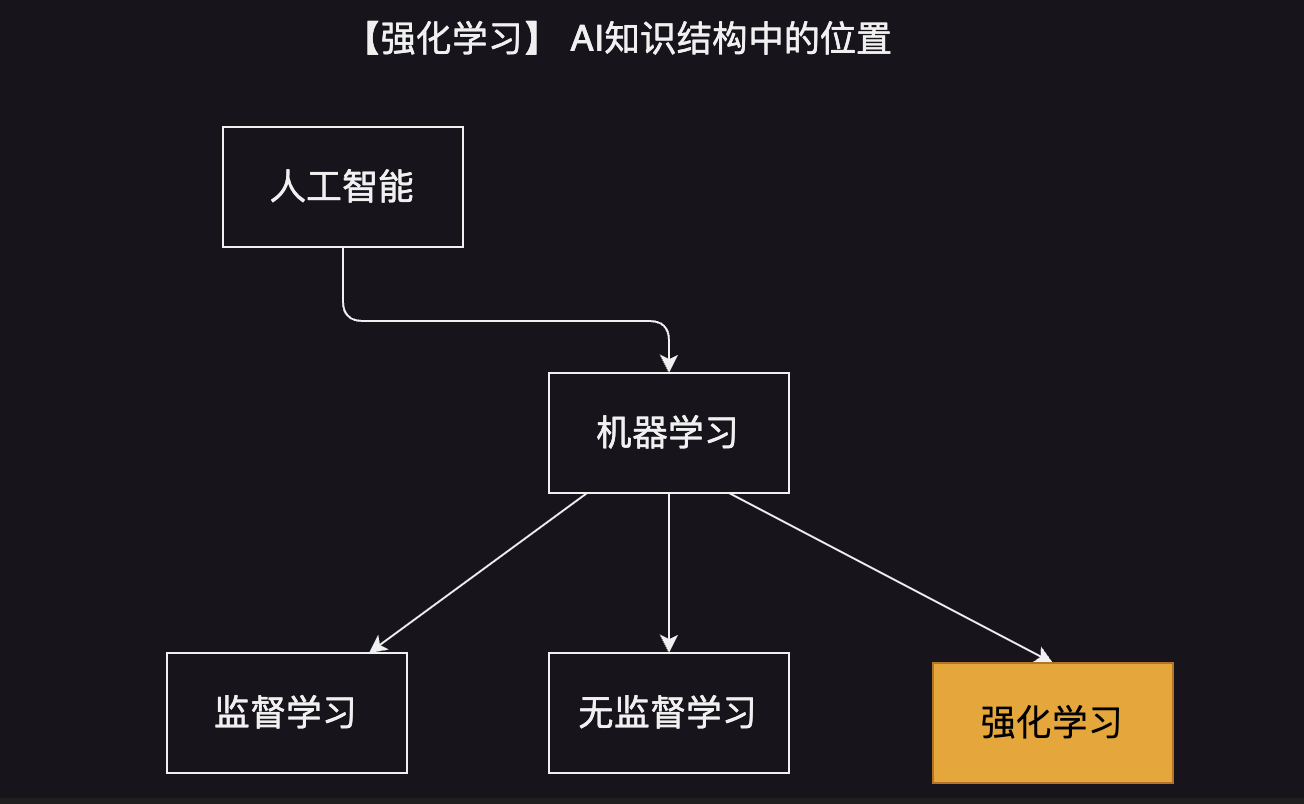
定义: 强化学习(reinforcement learning),又称再励学习、评价学习,是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。
百度百科: 在连接主义学习中,把学习算法分为三种类型,即非监督学习(unsupervised learning)、监督学习(supervised leaning)和强化学习。
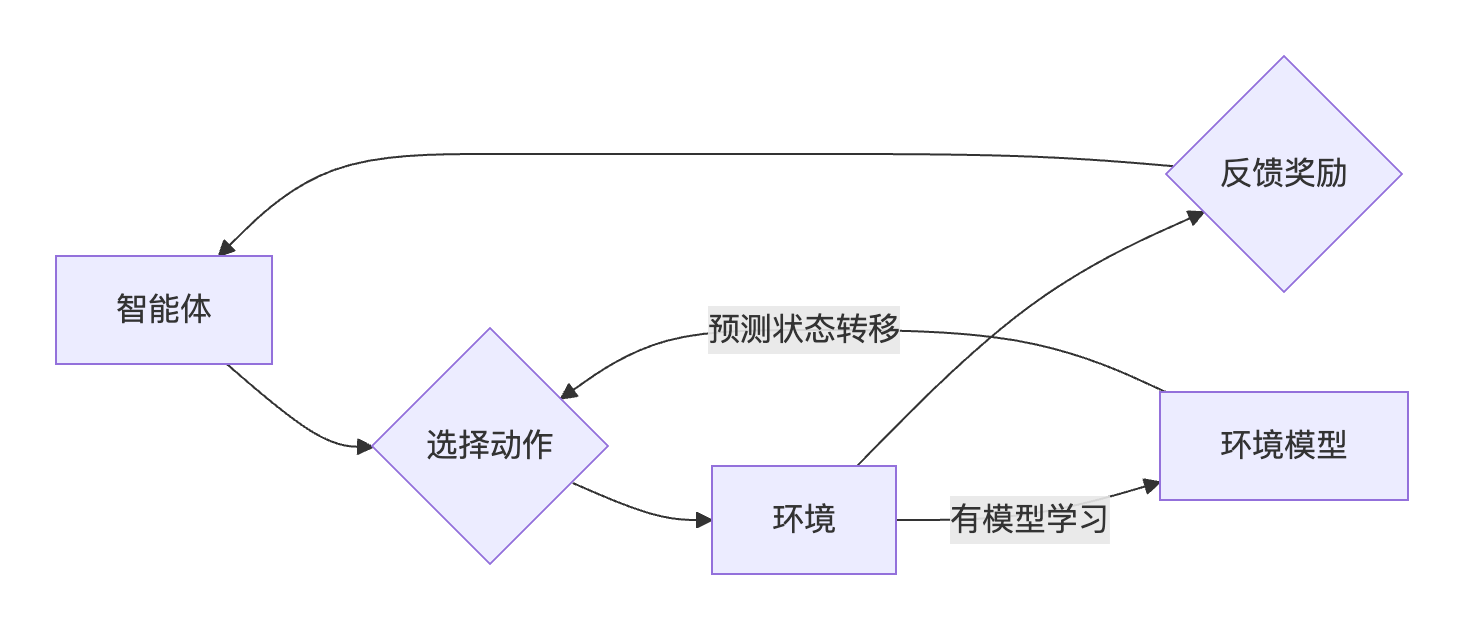
✅ 关键特征:奖励与惩罚
怎么做
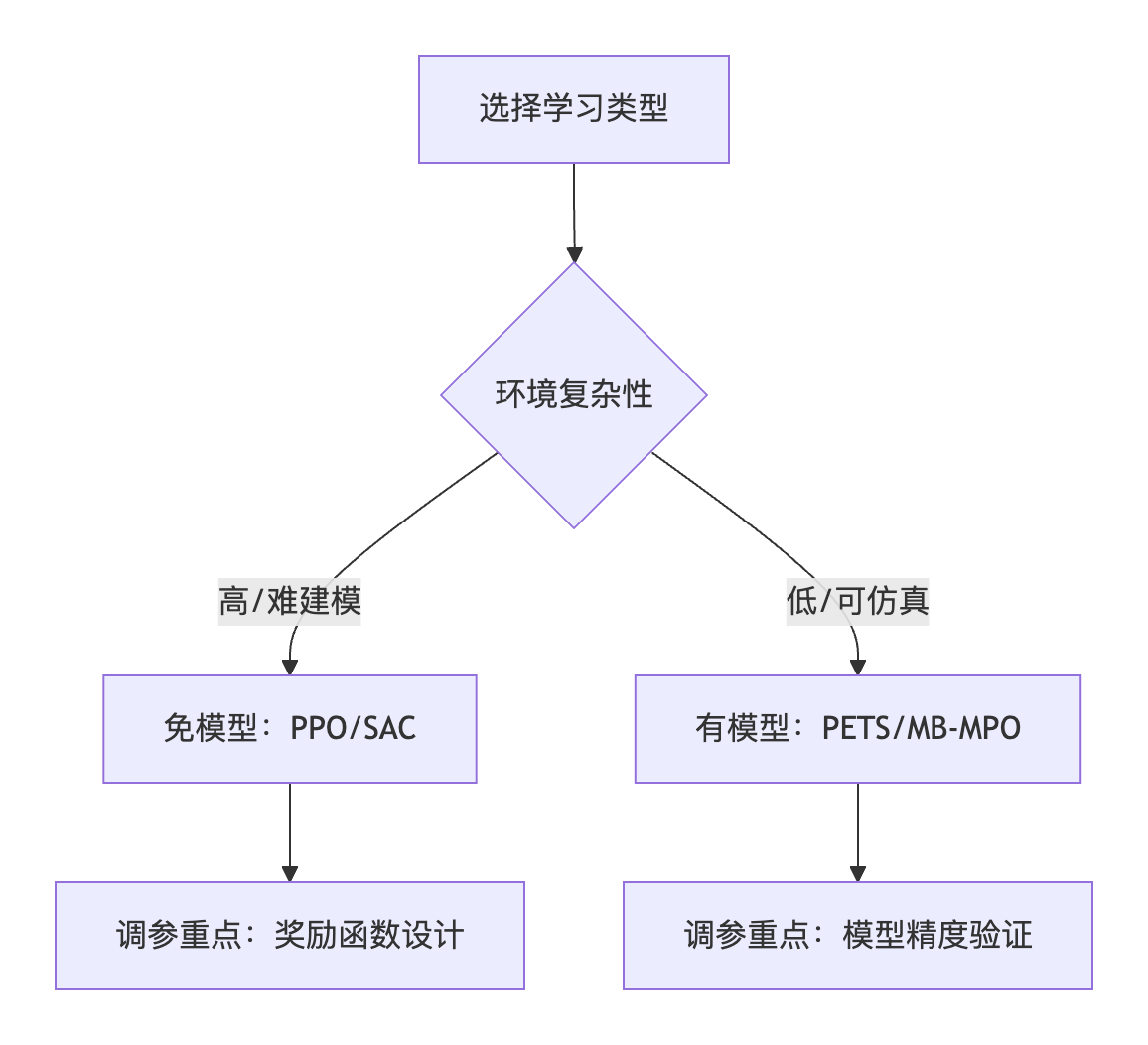
| 维度 | 免模型学习 (Model-Free) | 有模型学习 (Model-Based) |
|---|---|---|
| 核心思想 | 直接学习策略 | 先理解环境运作规则 |
| 工作方式 | 试错→记下最佳动作 | 构建环境模拟器→规划行动 |
| 计算成本 | 低(不需模拟环境) | 高(需建模环境动态) |
| 适用场景 | 环境复杂难建模(如股票交易) | 环境可精确仿真(如围棋) |
| 代表算法 | Q-Learning, DQN | 动态规划, MCTS |
| — |
- 免模型:当前状态 → 查表选最高Q值动作
- 有模型:当前状态 → 模拟未来N步 → 选最优路径
免模型学习
案例:学骑电动车
- 试错过程
- 右转时摔倒 → 惩罚(痛觉信号)
- 保持平衡前进 → 奖励(速度感)
- 关键特点:无需理解机械原理,靠肌肉记忆学习
有模型学习
案例:国际象棋对战
- 建模过程:
- 先背棋谱(学习“兵走直线,象飞斜角”规则)
- 大脑推演:“如果走车,对方可能有3种回应…”
- 关键特点:依赖对环境的精确认知
免模型和有模型算法区别:
应用案例
免模型案例:AlphaGo的走棋网络
- 输入:棋盘当前状态
- 输出:直接评估落子位置价值
- 优势:省去推演计算,每秒决策100+次
- 工具复现:OpenAI Gym围棋环境
有模型案例:特斯拉自动驾驶仿真
- 环境模型:
- 物理引擎模拟雨天路滑
- 神经网络生成行人行为
- 优势:0风险试错百亿次
- 开发框架:CARLA仿真平台
冷知识
- DeepMind用免模型 DQN 玩打砖块游戏,2小时超越人类水平,4小时发现开发者未预设的 挖地道秘籍
- 波士顿动力机器人摔倒时调整姿态的算法,本质是免模型的 策略梯度(PPO)
参考资料


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/daily/03.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
