
做一个有温度和有干货的技术分享作者 —— Qborfy
今天我们来学习 无监督学习
一句话核心:让AI在「没有标准答案」的数据中自己发现规律——像人类探索未知世界!
是什么?
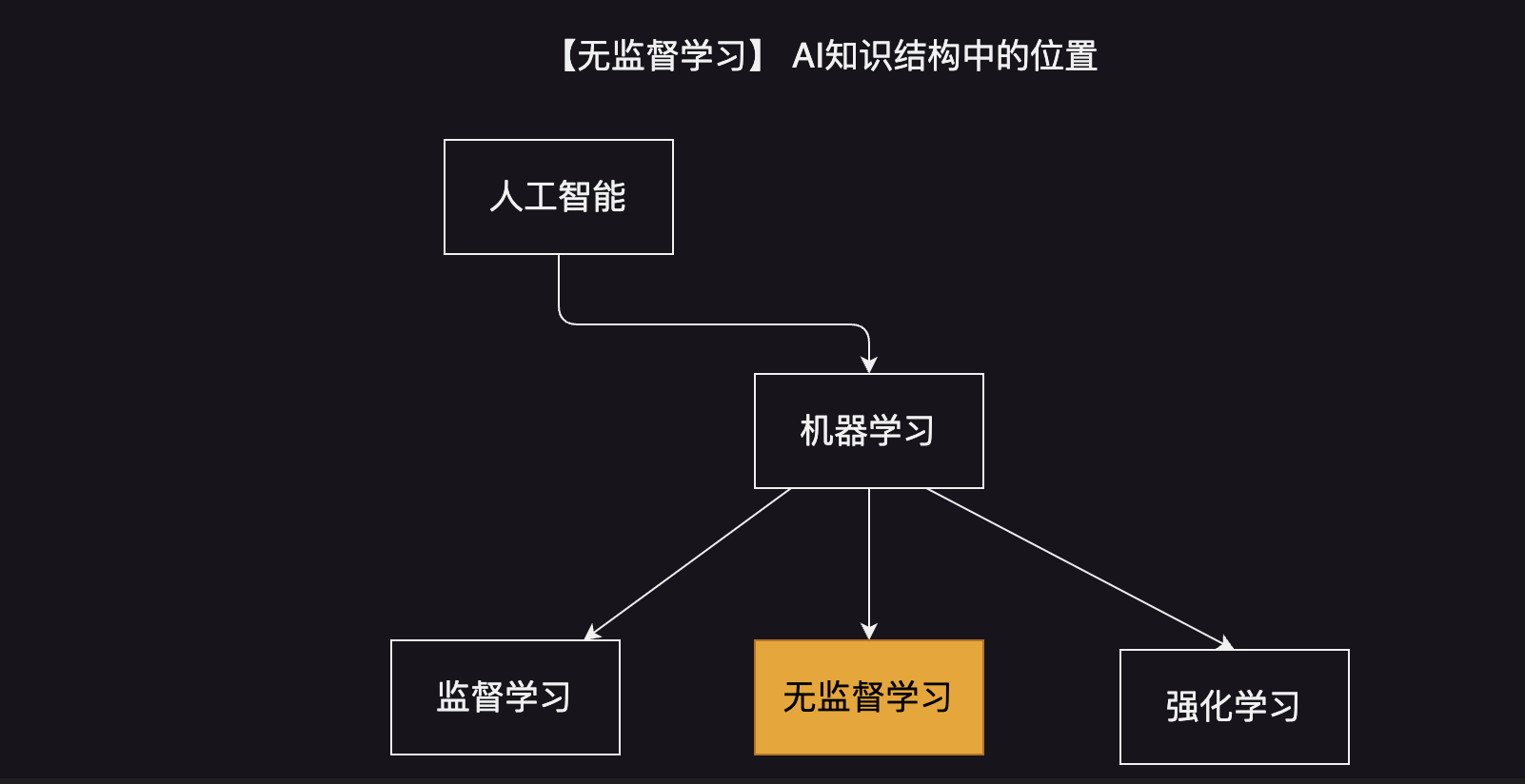
定义:从未标记数据中挖掘隐藏模式,通常采用聚类、降维、关联等算法去发现数据中的规律。
✅ 关键特征:无老师指导、数据无标签
❌ 常见误区 ≠ 完全不需要人类(仍需设计算法目标)
怎么做
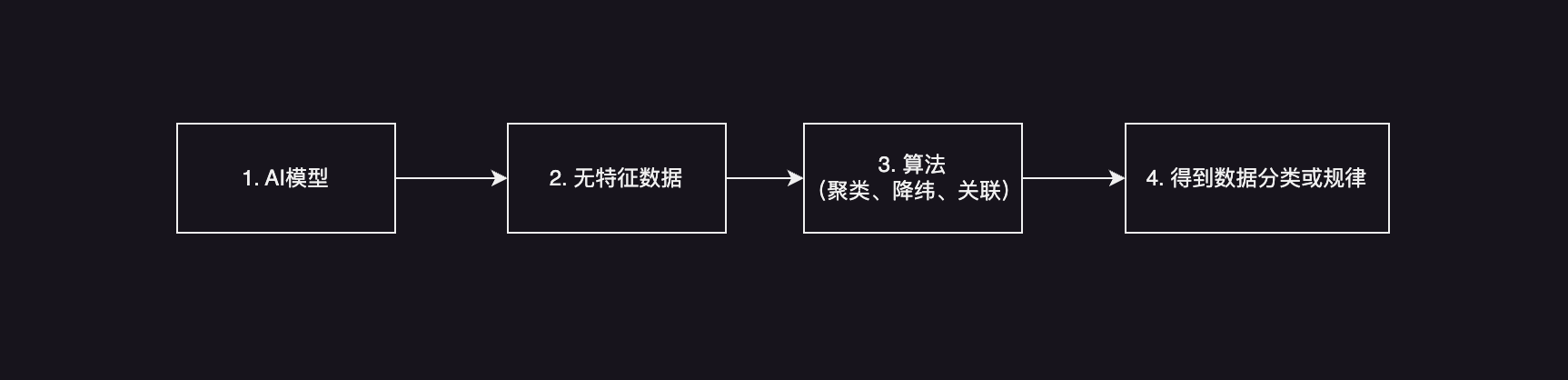
无监督学习,主要实现算法方案有以下三种:
- 聚类:相似数据分组
- 降纬:压缩数据特征
- 关联:发现数据关联规律
聚类(K均值聚类) —— 物以类聚
主要解决问题: “哪些东西本质相似?”
例子: 自助餐厅菜品自动分区
- 原始状态:200道菜杂乱摆放
- 聚类过程:
- ✓ 算法检测菜品特征(烹饪方式/食材/口味)
- ✓ 自动划分为:海鲜刺身区、川湘热炒区、西式烘焙区
- 价值:顾客5秒锁定目标区域
降维(PCA) —— 去芜存菁
主要解决问题: “如何简化复杂信息?”
例子: 购房决策简化模型
- 原始参数:20个维度(学区/通勤/绿化率/物业费…)
- 降维过程:
- ✓ 算法提取核心特征 → 教育资源指数 & 生活便利度
- ✓ 生成二维图谱
- 价值:半小时锁定目标房源
关联(Association)—— 发现隐藏规律
主要解决问题: “哪些事总一起发生?”
例子: 便利店商品摆放策略
- 原始数据:10万条购物小票
- 关联规则挖掘:
- {薯片,可乐} → {纸巾} [支持度=22%,置信度=81%]
- 规律:买零食饮料的顾客81%会顺手拿纸巾
- 价值:收银台旁放置纸巾架→ 纸巾销量+35%
动手实验
- 聚类实操:用
K-means GUI可视化分群过程 → 在线查看 - 降维对比:在
TensorFlow Embedding Projector看词向量压缩 → 在线查看 - 关联发现:通过Python实现超时购物车数据分析 →在线查看
实际案例
- 电商聚类:亚马逊用
DeepCluster算法将商品分成27万类(比人工分类多19倍) - 降维奇效:NASA用
t-SNE分析星系图像,将数据处理时间从3周缩短到4小时 - 关联暴利:7-Eleven发现
关东煮 + 清酒关联销售规律,冬季单店增收$6,800
参考资料


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/daily/02.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
