
做一个有温度和有干货的技术分享作者 —— Qborfy
一、概述
CodeBuddy 是腾讯面向开发者的基于 AI 大模型,提供代码生成补全、技术问答、智能代码评审、单测生成等能力,结合 Spec Kit(规范套件) 与 AI 能力,旨在通过“规范驱动+智能辅助”的模式,帮助团队统一代码风格、规避常见错误、提升开发效率。本指南将详细介绍从环境准备到日常开发的全流程操作,涵盖规范定义、AI 辅助编码、自动化检查与修复等核心场景。
1.1 Spec 是什么
传统开发 vs Spec-Driven 开发
很多开发者开始一个项目时是这样的流程:
💭 “嗯,我想要一个标签管理工具…”
💻 “开始写代码吧,边写边想”
🤖 “AI,帮我生成一个 React 组件…”
🐛 “等等,这个需求没想清楚啊”
🔄 “改需求、改代码、来回折腾…”
😫 “代码越来越乱,难以维护”
Spec-Driven 开发 的思路则完全不同:
💭 “我的问题是什么?我想要的真实需求是什么?”
📝 “写一份清晰的 Spec(规格书),定义问题的边界”
🤖 “基于 Spec,让 AI 精准理解需求并生成代码”
✅ “代码与 Spec 完全对齐,清晰可维护”
是什么?
Spec(规格) 简单来说,就是在开始编码前,用结构化的文档明确定义:
- 问题是什么: 用户的真实需求和痛点
- 解决方案长什么样: 功能描述、交互流程、数据模型
- 怎样判断成功: 验收标准和成功指标
- 有哪些约束: 技术限制、性能要求、安全规范
一个好的 Spec 应该包含:
| 步骤 | 作用 | 例子 |
|---|---|---|
| User Story | 定义用户需求 | “用户点击图标,能看到所有打开的标签页” |
| Acceptance Criteria | 清晰的验收条件 | “Given 打开 10 个标签,When 点击图标,Then 显示完整列表” |
| Data Model | 定义数据结构 | Tab、TabGroup、Summary 三个核心实体 |
| Functional Requirements | 功能需求列表 | FR-001: 系统必须检测所有打开的标签页 |
| Edge Cases | 边界情况处理 | “如果没有标签页,显示友好提示” |
| Success Criteria | 可测量的成功指标 | “渲染时间 <200ms,支持 100+ 标签” |
参考例子说明
❌ 没有 Spec,你可能这样 Prompt
1 | "给我写个 Chrome 扩展,能管理标签页,要好看" |
✅ 有 Spec,你可以这样 Prompt:
- “根据 spec.md,实现 TabList 组件,要求:- 显示 Tab[] 数组
- 支持虚拟滚动(超过 50 个标签时)
- 点击时调用 onTabClick 回调
- 按打开时间降序排列”
- …
二、快速开始
2.1 环境要求
- 操作系统:macOS 10.15+/Windows 10+/Linux (Ubuntu 20.04+)
- Node.js 版本:≥20.0.0
- 包管理器:npm/yarn/pnpm(任选其一)
- Python 版本:≥3.12
Nodejs 版本 nvm 安装操作命令:
1 | Mac | Linux安装命令 |
Python 版本管理器 uv 安装操作命令
1 | On macOS and Linux. |
2.2 安装 codebuddy-code
官方文档:https://www.codebuddy.ai/cli codebuddy 外网版(内网版有点问题,推荐使用外网版)
通过 npm 全局安装(推荐):
1 | npm install -g @tencent-ai/codebuddy-code |
2.3 安装 spec-kit(首次初始化项目使用)
spec 官方 github: https://github.com/github/spec-kit
1 | uv tool install specify-cli --from git+https://github.com/github/spec-kit.git |
2.4 配置 Codebuddy 语言偏好
CODEBUDDY.md 放在长期记忆的开头,项目特有的在后边追加(项目/CODEBUDDY.md)
如果同时在用 Codebuddy IDE 则 CODEBUDDY.md 可以放在自己的项目 rules 中,共享 CodebuddyCode 的长期记忆(.codebuddy/.rules)。
具体内容如下:
1 | # 指令集(Instructions) |
2.5 初始化项目 Spec 规范
进入你的项目根目录,运行初始化命令:
1 | cd /path/to/your-project |
第一次运行可能会出现错误:
解决方案就是前往 Github 申请令牌:
https://github.com/settings/personal-access-tokens
- 获取 token 声明到全局变量中:
1 | Mac | Linux进行导入配置变量,其中/root/.bashrc 为 Linux 系统本机的变量位置,如在 Mac 安装,默认地址为 ~/\.zshrc 或 ~/\.bashrc |
- 可以在命令后添加参数 –github-token=xxx
1 | specify init . --ai codebuddy --github-token=<KEY> |
完成初始化后,会在项目根目录生成 .specify和.codebuddy目录,具体如下:
1 | .codebuddy/ |
三、speckit 规范 AI 编程全流程
3.1 完整的 speckit 开发流程
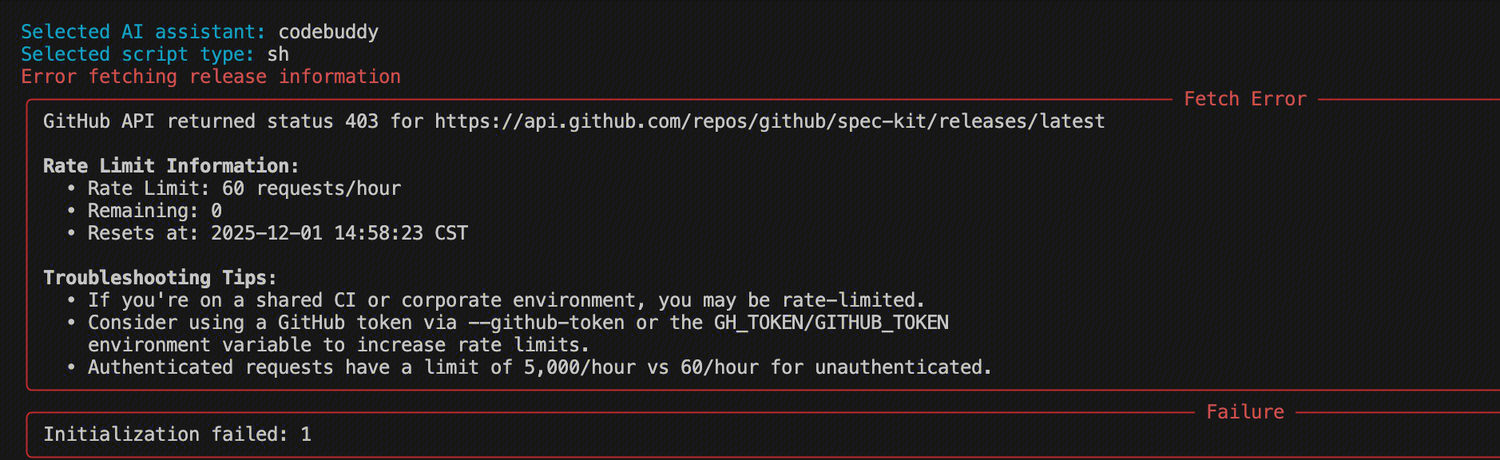
| 阶段 | 命令 | 目的 |
|---|---|---|
| 1 | /speckit.constitution |
定义项目的开发宪章(指导原则) |
| 2 | /speckit.specify |
编写初始功能规格文档 |
| 3 | /speckit.checklist |
验证规格质量是否达到“可交付”标准 |
| 4 | /speckit.clarify |
根据 checklist 结果进行需求澄清 |
| 5 | /speckit.plan |
进入实现规划,写技术方案 |
| 6 | /speckit.tasks |
基于 Spec 拆解技术方案为一个个可实现的任务点,方便 AI 执行 |
| 7 | /speckit.analyze |
确认任务的可实现和检查风险点 |
| 8 | /speckit.implement |
根据 constitution + spec + tasks 去实现代码输出 |
以上步骤可以多次执行,如:
/speckit.constitution可以针对项目,多次调整定义开发规范。/speckit.specify针对需求我们可以多次调整,直到生成的 spec.md 符合我们需求。/speckit.plan可以查看生成 plan.md 调整生成技术实现方案。- …等等
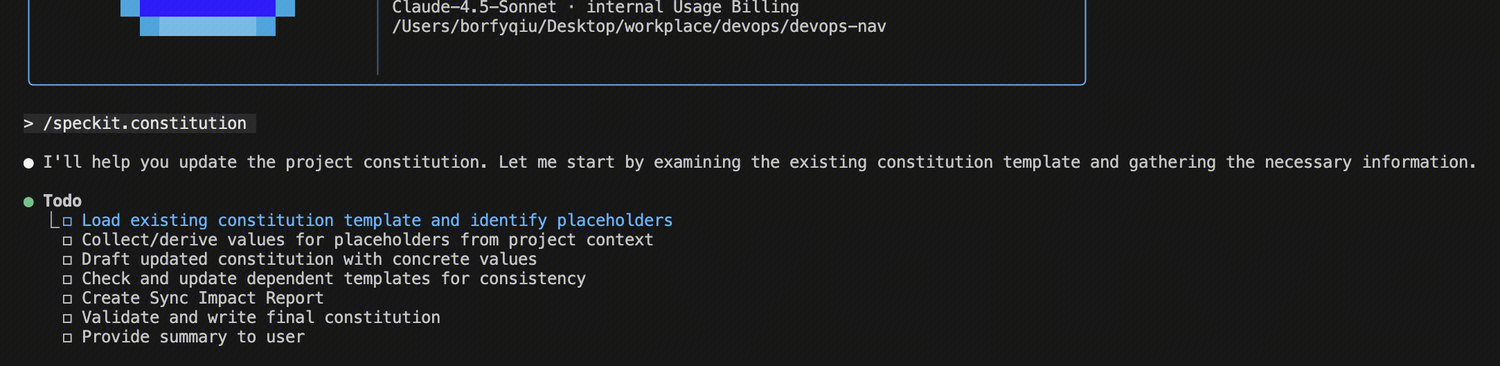
3.2 定义宪章 /speckit.constitution
宪章是项目的架构原则和约束的集合。它在整个开发过程中起到”守门员”的作用,确保所有设计决策都符合核心原则。
操作步骤
启动 codebuddy ,输入/speckit.constitution 这是一个xxx项目,主要使用技术栈为xxx ,具体如下图:
不同技术栈生成项目宪章是不一样,但主要包含以下内容:
- 项目主要技术栈
- 项目主要规范和约束
- 项目主要测试策略
- 其他一些约定规范等等
3.3 需求设计(/speckit.specify)和需求澄清(/speckit.clarify)
需求设计与澄清解决最大的问题:在开发设计前消除歧义与认知偏差,避免“带猜测”进入
/plan导致返工。
需求设计(/speckit.specify)
需求设计工作过程:
- 用户输入初步需求内容
/speckit.specify 需要实现一个xxx内容, 需求内容越仔细,AI 对此的疑问就越少。 - Spec 会根据需求生成“疑问列表”:模糊术语、未量化指标、冲突需求、缺失边界
- 让用户回答疑问列表,进行交互式问答(可能循环多轮)
- 记录决策与补充说明(形成“澄清日志”)
参考例子:
- 模糊指标 → 转化为量化:例如“高性能”→“P95 响应 < 300ms”。
- 冲突:Story A 说“匿名可用”,Story B 要求“强制登录”。
- 依赖外部系统 SLA 未说明。
- 安全责任归属不清。
下面实际操作,具体如下图:
需求澄清 (/speckit.clarify)
这里需求澄清 ≈ 需求评审,如果没有需求澄清那么开发流程如下:
1 | ❌ 开发者猜测 → 实现 A 版本 |
1 | 1 ❌ 开发者猜测 → 实现 A 版本 |
如果有需求澄清,那么就会这样子:
1 | 1 ✅ 结构化提问 → 明确所有歧义点 |
举例子说明:
输入模糊需求:”我需要新增一个页面去展示 tko 特有的域名列表”

Speckit 自动识别模糊点,并生成结构化的澄清问题。你逐一回答这些问题。

经过需求设计与澄清,我们就得到了一个清晰的需求文档,大概如下:
1 | # Feature Specification: TKO域名列表展示页面 |
这里会把需求澄清中所有内容都记录起来,如果你需要需求澄清过程越短,那么你在描述需求的时候,需求内容越清晰越好。
3.4 技术方案设计(/speckit.plan)
这一步主要把需求澄清好的内容拆分一个完整可以实现的技术方案,类似:从产品思维向工程思维的转换。
这一步会生成多个文件,具体说明如下:
1 | specs/001-tko-domain-list-page/ |
具体可以看其产出内容specs/001-tko-domain-list-page/plan.md:
1 | # Implementation Plan: TKO域名列表展示页面 |
3.5 生成任务清单 (/speckit.tasks)
这一步会根据前面的设计和规划,生成详细的开发任务清单,帮助团队高效地推进项目实施。
这一步其实也是开发中必不可少的部分,就是把技术方案拆成一个个可以真正实现的子任务。
因为从一个几百甚至上千行行的技术方案,如果没有一个可以真正实现的任务列表,AI 大模型陷入实现混乱。
具体可以看其产出内容tasks/001-tko-domain-list-page/tasks.md:
1 | ...... |
!!!注意: 这一步请仔细查看每个生成的步骤内容是否符合要求,如果不符合,请重新调整规划和技术方案。
3.6 检查任务清单(/speckit.checklist)
这一步是验证任务清单是否符合预期,是否可以实现。是可选步骤,如果不是必须的,可以跳过。
如果没有指定生成检查案例方向,会提出相关问答确定测试案例方向,最终会按照你的要求去生成测试案例。
最终会生成一个检查清单,具体可以看其产出内容tasks/001-tko-domain-list-page/checklist/implementation-readiness.md
1 | # 实施准备度检查清单: TKO域名列表展示页面 |
3.7 确认任务可实现(/speckit.analyze)
为什么?
在开始编码前,需要对整个方案进行全面的合规性检查:
✅ 所有用户故事都有对应的任务吗?
✅ 数据模型覆盖了所有需求吗?
✅ 宪章的所有原则都被满足了吗?
✅ 有遗漏的边界情况处理吗?
✅ 技术方案有风险点吗?
这个步骤主要让 AI 大模型去分析 上述生成 task 任务是否真正可以实现,有没有什么风险点?如下图所示:

3.8 开始实现 (/speckit.implement)
在真正执行之前,需要保证项目是可运行的,如:
前端项目:npm run dev 没有问题
后端项目:运行没有问题。
然后开始执行,等待 AI 自动编写代码,具体如下图所示:

以上就是基于spec-kitSDD 编程开发的全流程,具体可以参考spec-kit。
4. 最佳实践
| 场景类型 | 推荐流程 | 是否生成 spec.md | 是否生成 plan.md | 是否生成 tasks.md | 是否生成 checklist.md | 是否生成 analyze.md | 是否生成 implement.md |
|---|---|---|---|---|---|---|---|
| 常规需求 | Specify → Plan → Tasks → Analyze →Implement | 是 | 是 | 是 | 是 | 是 | 是 |
| 复杂 bug(跨模块) | Clarify → Plan → Tasks → Implement | 是 | 是 | 是 | 否(可引用旧 spec) | 否 | 是 |
| 小 bug(微逻辑、UI、配置) | Plan → Tasks → Implement | 否 | 否 | 否 | 否 | 否 | 是 |
| 配置错误 / 更新脚本 | Tasks → Implement | 否 | 否 | 否 | 否 | 否 | 是 |
5. 方案评估
经过上面的介绍,相信你已经对 SDD 有了一定的了解,下面我们来评估一下 Spec-Kit SDD 的优缺点。
5.1 优点
- 结构化开发:Spec Kit 强制执行结构化的、分步的软件设计流程(包括规范、计划、任务、实现),使整个开发过程更具纪律性。
- 减少“意图走样”:通过将需求转化为机器可读的 YAML 或 Markdown 规范文件,可以最大限度地减少传统开发流程中需求在不同阶段(需求 → 设计 → 实现)被误解的情况。
- 规范即“单一事实来源”:所有开发活动均以规范文件为准绳。当需求变更时,只需更新规范,然后重新生成计划和代码,避免了昂贵的代码重构。
- 改善协作和新人引导:安全策略、合规规则、设计系统约束等都写入规范,为团队提供了清晰的共享上下文,有助于团队协作和新成员快速上手。
- 模块化和可测试性:该方法将大型功能分解为原子的、可管理的任务单元,每个任务通常只涉及几个文件,提高了代码质量的一致性、可预测性和可审查性。
- 与现有工具集成:Spec Kit 是一个开源、模型不可知(model-agnostic)的工具包,可以与现有的 IDE(如 VS Code 的 Cursor 命令)、CI/CD 流水线以及多种 AI 模型(如 Claude Code)自然集成。
5.2 缺点
- 流程缓慢且成本高昂:整个过程需要生成大量的 Markdown 文档,可能非常缓慢,并且会消耗大量的 AI 模型 token(费用)。
- 变更困难:该流程依赖于前一步骤的输出。如果在流程中途(例如在实现阶段)想要修改规范,则必须重新生成计划和任务等后续所有文件,这个过程非常痛苦且繁琐。
- 文档负担重:对于喜欢快速迭代(vibe coding)的开发者来说,阅读和编辑大量的正式 Markdown 文档可能很无聊,感觉像是回到了传统的瀑布开发模型。
- 技术门槛较高:尽管学习曲线平缓,但有效使用 Spec Kit 仍需要相当高的技术知识水平和对架构原则的理解,需要知道最终的代码应该是什么样子。
- 适用场景有限:目前该工具最适合新项目(Greenfield work)或构建简单的原型。对于大型现有项目或需求频繁变更的项目,集成和维护成本很高。
6. 参考资料
- 《CodeBuddy Cli 官方说明文档》https://www.codebuddy.ai/docs/zh/cli/overview
- 《Specification-Driven Development (SDD) 规范驱动开发(SDD)》https://github.com/github/spec-kit/blob/main/spec-driven.md


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/ai-learn14.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
