
做一个有温度和有干货的技术分享作者 —— Qborfy
前面我们已经学习如何通过 Langchain调用独立部署的DeepSeek-R1:32b模型,且完成一些简单的应用,如: RAG 知识库的实现。
接下来我们学习如何通过LangChain实现一个Agent智能体,从而让 AI 模型帮忙实现做更多事情。
1. Agent智能体
1.1 是什么
在开发之前我们先来了解下Agent智能体是什么,它主要解决什么问题?
Agent是使用 LLM 大模型作为推理引擎的系统,用于确定应采取哪些行动(Action)以及这些行动输入应该是什么,然后会把行动的输出结果反馈给到Agent,用于判断是否需要更多行动或者结束然后输出返回。
结合网上的资料和个人理解,Agent智能体的出现主要是解决以下问题:
- LLM大模型与人类之间的交互是基于 prompt 实现的,prompt 是否清晰明确会影响大模型回答的效果
- LLM大模型只能进行推理,无法进行实际性的行动
- LLM大模型只能单独使用,无法结合多个 LLM 大模型进行组合使用
- LLM大模型只能输出文本,却无法符合用户需要的数据结构,如:如何标准的 JSON Schema
- LLM大模型只能依据当前输入进行推理,无法进行长期记忆
AI Agent是模仿人类思考技术,具体如下图所示:
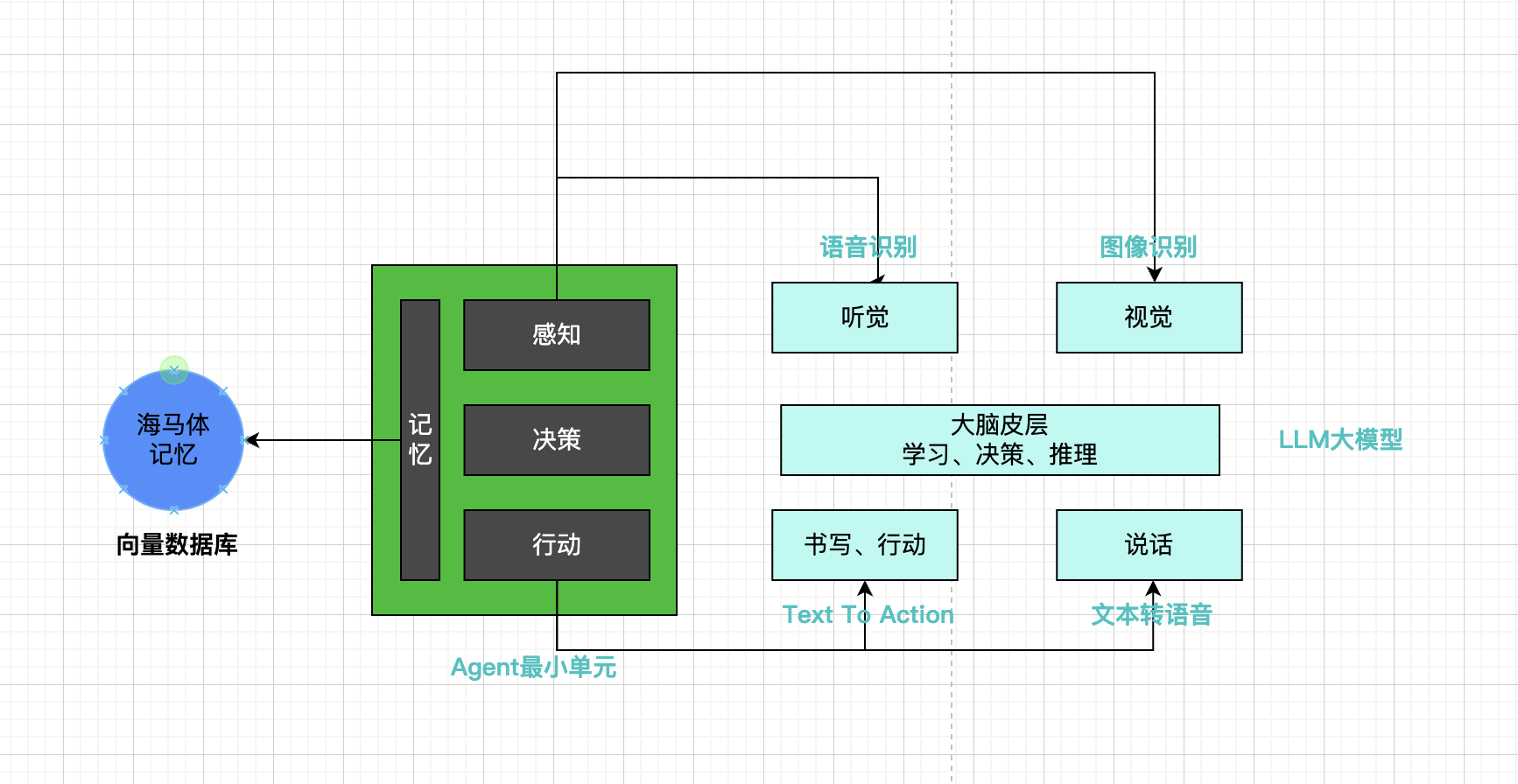
一句话弄明白,就是AI大模型可以作为一个大脑进行学习推理,但是 Agent技术利用 LLM大模型的推理能力,能根据人类输入,代替人类去做一些真正想要的事情,最后输出人类真正想要结果或者去执行某些行动。
为了更好理解 Agent技术, 我们可以看看目前AI协同工作类型,具体如下:
- Embbedding 模式: 人类输入目标,AI输出几个意见,人类自主决定采用哪个意见,代表产品为: RAG 智能客服机器人
- Copilot 模式: 人类输入目标,AI经过几个流程确定初步输出,人类可以自由调整输出,代表产品为: Copilot代码提示
- Agent 模式: 人类输入目标,AI 根据输入自主拆分任务,然后根据任务所需要的选择工具,最终完成任务最终结束,代表产品为: Manus AI 助手
1.2 怎么做
上面说到Agent技术是模仿人类思考技术,利用大模型进行推理,拆分人类输入的任务,那么 Agent其实最大的重点在于激发 LLM 大模型的推理能力,去拆分人类输入的任务。
那么如何激发 LLM 大模型的推理能力呢? 主要有以下几点:
1. Prompt 的思考链
思维链(Chain of Thoughts)已成为一种标准的提示技术,用于提高模型在复杂任务中的表现。模型被要求 “一步一步地思考”,将艰巨的任务分解为更小更简单的步骤。思维链将大任务转化为多个可管理的任务,并帮助人们理解模型的思维过程。
无思考链的 Prompt:
1 | 问:罗杰有5个网球,他又买了两盒网球,每盒有3个网球。他现在有多少网球? |
有思考链的 Prompt:
1 | 问:罗杰有5个网球,他又买了两盒网球,每盒有3个网球。他现在有多少网球? |
PS: DeepSeek的推理模式出来后,现在大部分模型默认就支持思考链的回答了。
思维树 是思维链的另一种表现形式,通过在任务的每一步探索多种推理可能性来扩展思维链。它首先将问题分解为多个思考步骤,并在每个步骤中生成多个想法,从而创建一个树状结构。试错和纠错在现实世界的任务决策中是不可避免且至关重要的步骤。自我反思帮助 AI Agent 完善过去的行动决策、纠正以前的错误、从而不断改进。主要可以包括以下几种模式:
- ReAct: 结合推理(Reasoning)和行动(Action),动态与环境交互。简单的理解就是: 推理+动作。
- Reflexion: 让 AI Agent 具备动态记忆和自我反思能力以提高推理能力的框架。简单的理解就是: 重复步骤(记忆+推理+动作)。
- Hindsight: 利用已知结果优化过去决策,从失败经验中学习。简单理解就是: 根据已知结果进行反向推理。
2. 记忆
记忆模块负责存储信息,包括过去的交互、学习到的知识,甚至是临时的任务信息。
AI有了记忆后,就可以根据已知的记忆知识去更好回答用户提问。而在 AI Agent 定义里:
用户在与其交互过程中产生的内容都可以认为是 Agent 的记忆,和人类记忆的模式能够产生对应关系。
记忆可以分为几类:
- 感觉记忆: 初始输入文本、图片等数据,如:看一张照片后,当不看照片,还能想起照片的印象,这是感觉记忆
- 短期记忆: 本次与 AI 对话的上下文,如:进行记忆几个数字,短期内还是可以记住这几个数字,这就是短期记忆
- 长期记忆: Agent在工作时需要查询向量数据库,如:学会骑自行车,及时很长时间没骑自行车,但是骑自行车这个技能还在,那么骑自行车这个技能就是长期记忆
而针对记忆这方面的技术, Embedding 技术和向量相似度计算就是记忆(向量数据库的核心),具体可以做以下理解:
- Embedding 技术:将文本、图片等数据转换为向量,从而实现记忆功能
- 向量相似度计算:通过数学方法来计算两个向量之间的相似度,常见的算法有:余弦相似度、欧式距离、汉明距离等,通过相似度计算可以判断两个向量是否相似,从而获取我们所需要的记忆数据
3. 工具
AI 懂得使用工具才会更像人类。
AI Agent 除了记忆,还需要在获取到每一步子任务的工作后,Agent 都会判断是否需要通过调用外部工具来完成该子任务,并在完成后获取该外部工具返回的信息提供给 LLM,进行下一步子任务的工作。
目前AI 大模型接入工具的使用方式如下:
- 函数调用(Function Call): 向大模型描述函数,如:函数的作用和参数结构(如:JSON对象),从让 AI 大模型在执行任务能够调用外部工具,如:
open("test.txt") - 插件系统(Plugin):通过标准化接口扩展大模型能力,等同于公共的函数调用,让大家都能用。
- 模型内嵌工具: 不同模型会提供不同内置工具,如:OpenAI 的
file_search和code_interpreter,能AI直接调用去搜索文件和解析文件的能力。
目前绝大部分 AI Agent开发使用的工具的方式都是 Function Call的方式,目前主流大模型基本都支持这个能力,具体如下:
| 模型 | 支持Function Call | 说明 |
|---|---|---|
| GPT-4 Turbo、GPT-4o、GPT-3.5 Turbo | 是 | OpenAI 系列模型,闭源 |
| Claude 3(Opus/Sonnet/Haiku)、Claude 3.5 | 是 | Anthropic 系列模型,闭源 |
| Gemini Pro、Gemini 1.5 Pro、Gemini Flash | 是 | OpenAI 系列模型,闭源 |
| Llama 3(8B/70B)、Llama 3.1 | 是 | Meta Llama 系列,开源, 需要微调后才支持,不过有现成的 Gorilla 微调框架 |
| Mistral Large、Mistral-7B-Instruct | 是 | Mistral AI 系列,开源,轻量级模型适合本地部署 |
| 通义千问(Qwen-Chat) | 是 | 阿里云系列 ,开源,基于 ReAct Prompting 原理优化工具 |
| GLM-Z1-32B-0414、ChatGLM3-6B | 是 | 清华智谱系列模型,开源 |
| DeepSeek V3 | 是 | DeepSeek,开源,专为函数调用优化,支持多工具协同 |
2. Langchain AI Agent开发实战
完整了解 Agent的知识后,解析来我们要通过Langchain框架去实现一个 AI Agent,获取获取当天的龙虎榜数据。
2.1 基础概念
langchain_core.tools.tool: Langchain用来创建工具的方法langchain.agents.create_tool_calling_agent: 创建工具调用Agent的函数langchain.agents.AgentExecutor: 创建 Agent执行器的类
开始实现思路如下:
- 编写工具函数和工具描述
- 创建LLM模型
- 创建符合工具调用Agent的Prompt
- 创建Agent和 AgentExecutor
- 通过LangSmith查看 Agent执行过程(调试使用)
2.2 工具声明
获取当前日期
接下来我们声明一个工具函数,用于解决大模型无法判断当前的日期。
1 | from langchain_core.tools import tool |
获取龙虎榜数据
1 | from pydantic import BaseModel, Field |
2.3 创建LLM模型
不同的模型对于工具调用不同, 目前已知支持最好的模型是GPT-4 Turbo, 但是这个模型是闭源的, 国内支持较好是 DeepSeek但是也收费,对于调试模型更加友好可以利用g模型厂商 - siliconflow AI 云服务平台,从而减少我们的调试成本。
1 | from langchain_openai import ChatOpenAI |
2.4 创建Prompt
Prompt对于LLM大模型的实现有关键作用, 其中agent_scratchpad的占位符对于 AI 大模型实现非常重要,主要用于 记录和传递 Agent 执行过程中的中间推理步骤,同时还会强制按照 tool所需要的参数进行输入调用。
Prompt 具体实现如下:
1 | from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder |
2.5 创建Agent和 AgentExecutor
创建Agent, Langchain也提供不同的类型,如下:
- Tool Calling Agent (create_tool_calling_agent) : 依赖模型原生工具调用能力,自动将工具描述注入模型上下文, 直接返回工具调用参数对象,部分LLM模型支持
- ReAct Agent (create_react_agent) : 遵循 Thought → Action → Observation 循环,每步根据上下文选择工具,结合自然语言与工具调用
- Structured Chat Agent (create_structured_chat_agent):必须遵循预定义响应模板,严格匹配工具参数格式,通常一次性完成工具选择
目前我们使用的是 create_tool_calling_agent, 具体实现如下:
1 | from langchain.agents import create_tool_calling_agent, AgentExecutor |
PS:
handle_parsing_errors: 当 Agent执行发生异常的时候,如传入参数不符合工具描述,是否抛出异常,当为 True错误信息会通过 intermediate_steps 传递到下一轮推理,模型基于历史步骤中的错误反馈重新生成正确的工具调用指令verbose: 是否打印中间步骤,从而更好的理解模型推理过程
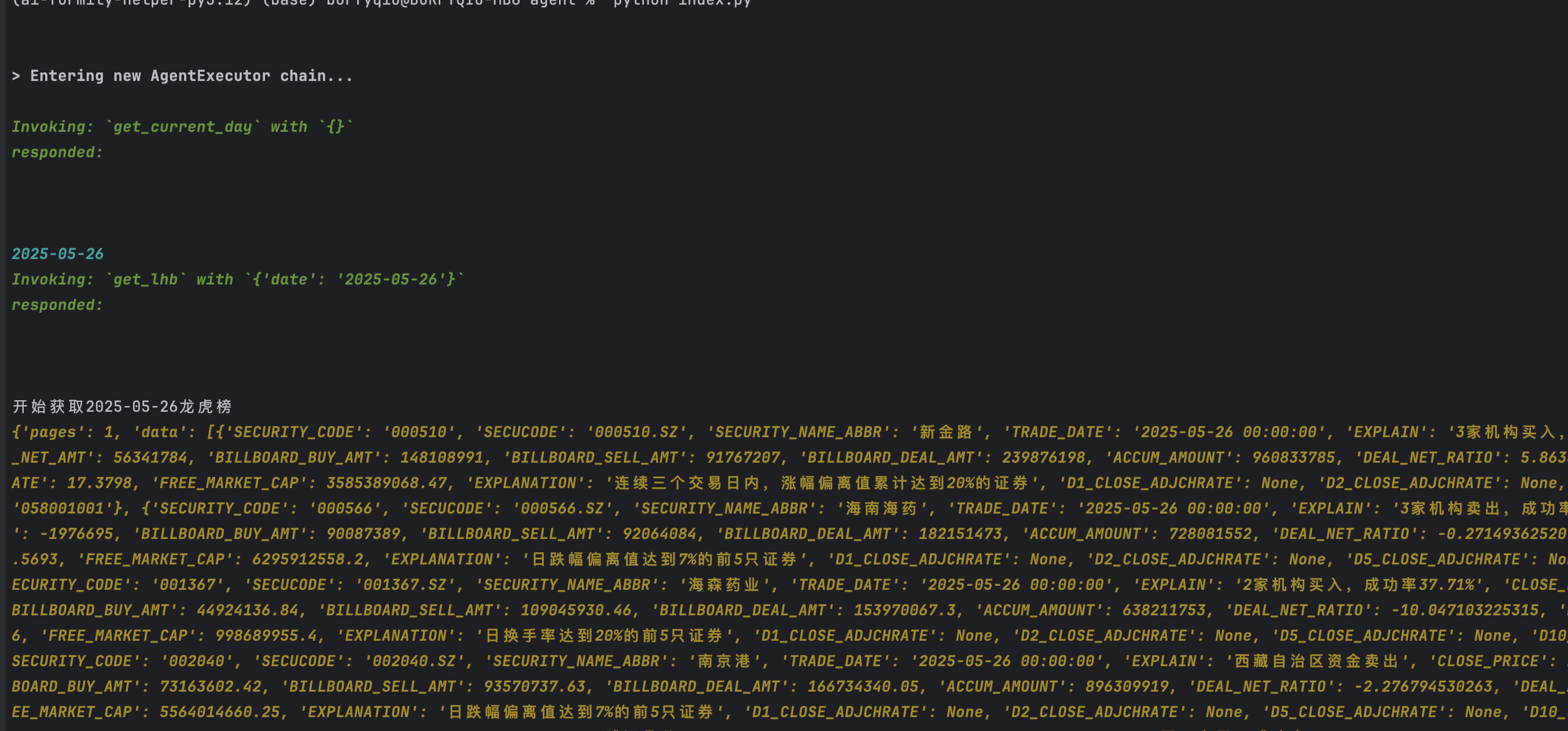
以下是完整代码实现过程截图:

2.6 Smith调试
在 Agent中避免不了调试,尤其不同大模型对于工具的调用和判断是不一样的,同时执行过程异常 Langchain也比较难定位,所以因此我们可以使用LangSmith进行调试。
前往LangSmith官网,注册账号,创建项目,获取API_KEY,设置环境变量,具体如下:
1 | # 设置LangSimth 环境变量 |
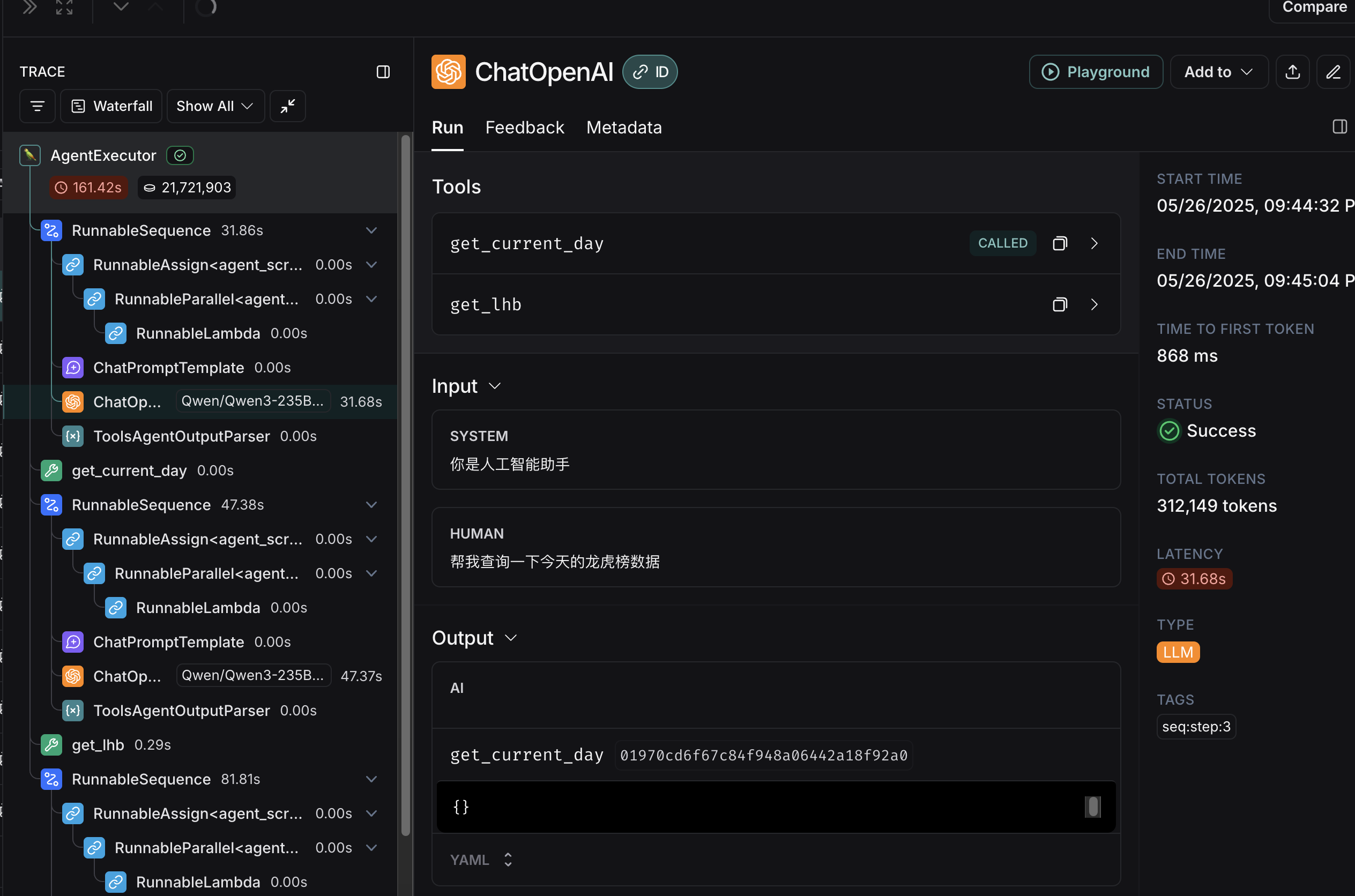
再次运行Agent,可以前往LangSmith查看调试结果,如下图所示:
3.总结
AI Agent的实现,对于我们来说,可以更好的理解大模型的能力,同时也可以更好的利用大模型能力,从而更好的实现业务场景。 回顾一下,AI Agent的知识点:
- AI Agent是利用 AI 大模型的推理能力,结合记忆+工具调用能力,实现扩展 AI 大模型能力的一种技术方案
- 实现 AI Agent的方案有目前主流是通过大模型 Function Call
- 实现 AI Agent中的 Prompt中,
agent_scratchpad占位符是非常重要,记录和传递 Agent 执行过程中的中间推理步骤,同时还会强制按照 tool 所需要的参数进行输入调用。
以上就是 AI Agent的实现过程,希望对你有所帮助。
参考资料
- LangChain官方文档
- LangChain中文教程
- LangChain(0.0.340)官方文档十一:Agents之Agent Types
- (哔哩哔哩视频)2025吃透LangChain大模型全套教程(LLM+RAG+OpenAI+Agent)通俗易懂,学完即就业!
- Langchain Agent - Agent类型说明
- 万字长文解析AI Agent技术原理和应用
声明:本文部分材料是基于DeepSeek-R1模型生成。


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/ai-learn09.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
